
Dexter is a platform for studying bi-manual dexterity designed to help us
study the acquisition of concepts
and cognitive representations from interaction with the world. We are
addressing central issues in cognitive science and artificial intelligence:
the origins of conceptual systems, the role of native structure, computational
complexity issues, and knowledge representation. The goal of the research is
to advance computational accounts for sensorimotor and cognitive development
in a manner that leads to new theories for controlling intelligent robots, and
provides a basis for shared meaning between humans and machines. Research is
underway toward mechanisms for learning hierarchical control knowledge -
categories of objects, activities, tasks, and situations - through a
continuous interaction with the environment.
Each 3 fingered Barrett hand has 4 DOF and has integrated tactile load
cells (ATI) on each fingertip. Three VME cages host the computing system to
control the integrated platform
The BiSight head consists of 4 mechanical DOF (head pan-tilt and independent
verge), 3 optical degrees of freedom (focus, iris, and zoom), and an
integrated, binaural acoustic sensor consisting of four microphones for
localizing and interpreting acoustic sources.
Grasp planning for multiple finger manipulators has proven to be a very
challenging problem. Traditional approaches rely on models for contact
planning which lead to computationally intractable solutions and often do not
scale to three dimensional objects or to arbitrary numbers of contacts. We
have constructed an approach for closed-loop grasp control which is provably
correct for two and three contacts on regular, convex objects. This approach
employs "n" asynchronous controllers (one for each contact) to achieve grasp
geometries from among an equivalence class of grasp solutions. This approach
generates a grasp controller - a closed-loop, differential response
to tactile feedback - to remove wrench residuals in a grasp configuration.
The equilibria establish necessary conditions for wrench closure on regular,
convex objects, and identify good grasps, in general, for arbitrary objects.
Sequences of grasp controllers, engaging sequences of contact resources can be
used to optimize grasp performance and to produce manipulation gaits .
The result is a very unique, sensor-based grasp controller that does not
require a priori object geometry.
Here is an example of the Utah/MIT hand rolling a can:
Click here to see a movie of the hand
rolling the can (as above), and here
to see a movie of the Utah/MIT hand performing an ordinary household chore.
Additional publications can be found on the lab publications page.
Mechanism
 Dexter consists of two Whole Arm Manipulators (WAMs) from
Barrett
Technologies, two Barrett Hands, and a BiSight stereo head.
The WAMs are 7 DOF manipulators with roughly anthropomorphic geometry. Each
degree of freedom is actuated through braided steel tendons through a low
ratio transmission. This configuration leads to a combination of excellent
velocity, acceleration, and back-drivability. The last of these
properties means that contacts anywhere on the arm are detectable as actuator
"effort." We aim to use this property to implement "whole-body" grasping
algorithms.
Dexter consists of two Whole Arm Manipulators (WAMs) from
Barrett
Technologies, two Barrett Hands, and a BiSight stereo head.
The WAMs are 7 DOF manipulators with roughly anthropomorphic geometry. Each
degree of freedom is actuated through braided steel tendons through a low
ratio transmission. This configuration leads to a combination of excellent
velocity, acceleration, and back-drivability. The last of these
properties means that contacts anywhere on the arm are detectable as actuator
"effort." We aim to use this property to implement "whole-body" grasping
algorithms.

Grasping and Manipulation
![]()
Robust Finger Gaits from
Closed-Loop Controllers




Torso Movies
Grasping Cylinders: Top Approach

grasp_top.mov
Grasping Cylinders: Side Approach
2 fingers form a virtual finger

grasp_peanutbutter.mov
Whole Body Grasping

wbg_move_left.mov
Learning Grasp Location Affordances

grasp_afford.mov
Related Publications

Learning Features for Prospective Control
In Psychology, "prospective behavior" is observed when a subject
modifies their behavior in a manner that circumvents future problems.
In robotics, these kinds of tasks are used to study so-called
"pick-and-place" constraints in planning problems - such as when some
choices for picking an object up are incompatible with subsequent
opperations that must be performed, like putting it down, for instance.
To see prospective feature discovery unfold, psychologist
recording the type of errors infants make during a longitudinal
learning experiment. Infants (with a dominant hand preference) are
presented with a spoon, laden with applesauce with the handle pointed
left and right.

Infant subjects will make predictable mistakes as a function of age when they try to get the applesauce into their mouths.
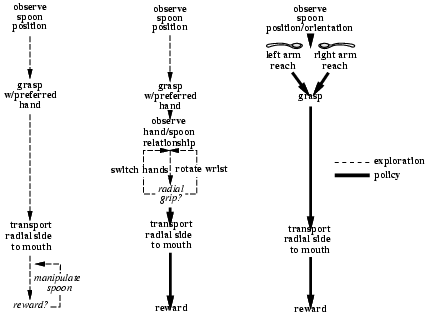 At 9 months (leftmost column in the diagram), they often try the
dominant hand grasp erroneously, only noticing when the handle of the
spoon enters their mouth (a distinguishing tactile event). At 14
months (the middle column), they notice that they have chosen the
wrong hand after the grasp but before they put it in their mouth (this
is presumably a visual trigger). At 19 months (the rightmost column),
they select the correct hand for the grasp (also, presumably the
result of learning to recognize a prospective visual event).
At 9 months (leftmost column in the diagram), they often try the
dominant hand grasp erroneously, only noticing when the handle of the
spoon enters their mouth (a distinguishing tactile event). At 14
months (the middle column), they notice that they have chosen the
wrong hand after the grasp but before they put it in their mouth (this
is presumably a visual trigger). At 19 months (the rightmost column),
they select the correct hand for the grasp (also, presumably the
result of learning to recognize a prospective visual event).
This work suggests that human infants learn task constraints
through exploration and that they anticipate future contraints by
the progressive incorporation of perceptual information.
|
|
McCarty, M. E., Clifton, R. K., & Collard, R. R. (2001). The beginnings of tool use by infants and toddlers Infancy, 2:233-256. |
|
|
McCarty, M. E., Clifton, R. K., & Collard, R. R. (1999). Problem solving in infancy: The emergence of an action plan Developmental Psychology, 35(4):1091-1101 |
 We have implemented a reinforcement learning system for discovering
and incorporating prospective features into robot control policies
on the LPR humanoid. Our experimental apparatus looked like the picture to
the left. A peanut butter jar is presented with the red lid oriented left or
right. The robot must learn controls that grasp the jar and put it down
right-side-up on the table. It receives external reward for putting it down
correctly and is not allowed to release the jar if it is upside down.
We have implemented a reinforcement learning system for discovering
and incorporating prospective features into robot control policies
on the LPR humanoid. Our experimental apparatus looked like the picture to
the left. A peanut butter jar is presented with the red lid oriented left or
right. The robot must learn controls that grasp the jar and put it down
right-side-up on the table. It receives external reward for putting it down
correctly and is not allowed to release the jar if it is upside down.
We pre-trained our robot to be a "southpaw" (to simulate dominant hand preferences in human infants) and then watched the type of transient errors that occurred during training before the final policy is completed. We observed a similar chronology as cited in the psychology work above. Click on these examples to see movies of the robot at various stages in development. You can get all the details in:
|
|
Wheeler, D., Fagg, A. H., Grupen, R., Learning Prospective Pick and Place Behavior. |
| Left Presentations Only: Prior to Learning | 
|
applesauce3-easy-other-final.mov
applesauce3-easy-other-final.mp4 applesauce3-easy-other-final.avi
|
| Left Presentation Only: Strategy After Learning | 
|
applesauce1-easy-final.mov
|
| Both Orientations Presented: Before Learning | 
|
applesauce4-hard-late-final.mov
applesauce4-hard-late-final.mp4 applesauce4-hard-late-final.avi
|
| Both Orientations Presented: During Learning | 
|
applesauce8-hard-early-final.mov
applesauce8-hard-early-final.mp4 applesauce8-hard-early-final.avi
|
| Both Orientations Presented: After Learning | 
|
applesauce7-hard-optimal-final.mov
applesauce7-hard-optimal-final.mp4 applesauce7-hard-optimal-final.avi
|
|
The remote teleoperation of robots is one of the dominant modes of
robot control in applications involving hazardous environments,
including space. Here, a user is equipped with an interface that
conveys the sensory information being collected by the robot and
allows the user to command the robot's actions. The difficulty with
this form of interface is the degree of fatigue that is experienced by
the user, often within a short period of time. To alleviate this
problem, we are working with our colleagues at the
NASA Johnson Space
Center to develop user interfaces that anticipate the
actions of the user, allowing the robot to aid in the partial performance of the task, or
even to learn how to perform entire tasks autonomously.
Our approach is to use our automatic control techniques to aid in the recognition of the user's actions. Prior to the user demonstration, the control system enumerates the different grasping actions that can be used for each object in the workspace (essentially, the robot "imagines" what it would feel like to pick up every object). The movements produced by the user are then compared against each of these imagined actions. The one action that best matches the user-driven movement is considered to be the explanation of that movement. Using this technique, we are able to recognize entire sequences of actions.
|

|
| Demonstration of a sequence by a user through a teleoperation interface. In this example, the extracted sequence is: pick up the blue ball; place it on the pink target, pick up the yellow ball, and place it on the orange target. | 
|
sequence_learn_v2_demo.mov
sequence_learn_v2_demo_small.avi
|
| Automated replay of the same action sequence in a novel situation. Note that the movements are smoother and are executed more quickly than when the user is in control. |

|
sequence_learn_v2_D.mov
|

This approach leads to robots that develop manual dexterity as result of cumulative practice in the domain. We are transfering this technology to Johnson Space Center, Houston for use on the NASA Robonaut.

Copyright © 2000
Laboratory for Perceptual Robotics at UMass< Amherst.
All rights reserved.