
The Laboratory
for Perceptual Robotics experiments with computational
principles underlying flexible, adaptable systems. We are concerned
with robot systems that must produce many kinds of behavior in
nonstationary environments. This implies that the objective of
behavior is constantly changing as, for instance, when battery levels
change, or when nondeterminism in the environment causes dangerous
situations (or opportunities) to occur. We refer to these kinds of
problem domains as open systems - they are only partially
observable and partially controllable. To estimate hidden
state and to expand the set of achievable control transitions, we have
implemented temporally extended observations and actions,
respectively.
The kinds of world models developed in such systems are the product of
native structure, rewards, environmental stimuli, and experience.
We also consider redundant robot systems - i.e. those that
have many ways of perceiving important events and many ways of
manipulating the world to effect change. We employ distributed
solutions to multi-objective problems and
propose that hierarchical robot programs should be acquired
incrementally in a manner inspired by sensorimotor development
in human infants. We propose to grow a functioning machine
agency by observing that robot systems possess a great deal of
intrinsic structure (kinematic, dynamic, perceptual, motor) that
we discover and exploit during on-going interaction with the
world.
Finally, we study robot systems that collaborate with
humans and with other robots. A mixed-initiative system can take
actions derived from competing internal objectives as well as from
external peers and supervisors. Part of our goal concerns how such a
robot system can explain why it is behaving in a particular way
and can communicate effectively with others.
To address this goal, we integrate a collection of existing
mathematical and computational frameworks for robot systems that grow
knowledge structures grounded in activity and use them to make
intelligent choices. The major pieces of this integrated framework are
summarized in our glossary of terms
and techniques for constructing intelligent robots that acquire world
models from life-long interaction with humans, robots, and complex,
non-deterministic worlds.
The BEAST architecture has been developed at UMass to provide a
computational account of sensorimotor development for use in robot
programming. "Best-Effort" in the acronym refers to constraints related to
embodiment of the robot systems; sensory and motor systems, the suite of
reflexes derived from the control basis, the state of existing control
knowledge, and the influence of peers and supervisors.
Best-Effort Adaptive-Optimal Sensorimotor Transformations (BEAST)
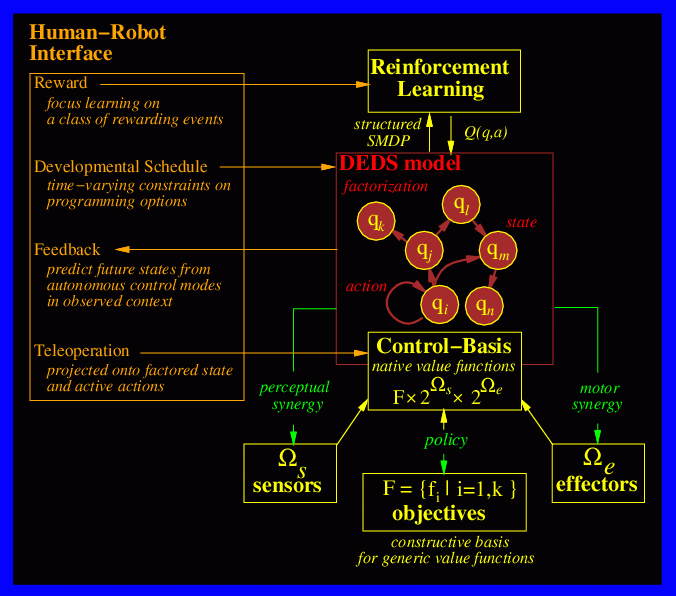
Figure 1: BEAST - Best-Effort Adaptive-Optimal
Sensorimotor Transformations
The agent's most primitive actions are closed-loop controllers that are asymptotically stable and whose behavior is dominated by a discrete set of stable fixed points. This design is consistent with current research in infant motor development, adult motor control and robotics. A closed-loop "action" is computed by continuously observing dependent variables with sensors and executing a greedy descent of objective functions F using independent effector variables. The control basis (Figure 1) is a generative basis for constructing such actions in the form of simple tracking controllers with references specified by events on sensory streams. The objective function is minimized by actuating some combination of the available effectors,
The transient response of a closed-loop action can be used to classify the environmental stimuli that drive it. For example, if control error is growing, then the subject we are tracking is too fast. We are attempting to use prototypical patterns in the dynamic response to distinguish important environmental contexts. Therefore, a controller, in our parlance, produces both mechanical artifacts and information regarding the environmental context during temporally extended interactions with it. A state vector (q in Figure 1) is a list of previously acquired dynamic models that could explain a series of run-time observations.
This approach yields a Markov Decision Process (MDP) as illustrated in Figure 1. Machine learning techniques based on MDPs like reinforcement learning (RL) are employed to learn policies for sequencing control decisions in order to optimize reward. The learning algorithm solves the temporal credit assignment problem by associating credit with elements of a behavioral sequence that lead to reward. However, RL depends on stochastic exploration and our state space could be enormous for interesting robots. Moreover, any algoithm that depends on completely random exploration will take a long time, and will occassionally do something terribly unfortunate to learn about the consequences.
The Human-Robot Interaction (HRI) Interface provides many opportunities to interact with learning robots. A Discrete Event Dynamic System (DEDS) model in Figure 1 can be implemented to analyze and interact with the processes for acquiring behavior. Axioms in a DEDS framework can be used to prove that certain predicate states can't occur by pruning the set of admissible actions. In a sense, the DEDS specification uses controllers to avoid uncontrollable states. But it can also be used to shape the early formation of a skill as in classsical approaches to shaping and maturation. The HRI also allows users to impose an external reward metric to generate a value function on legal states and admissible actions. Teleoperator inputs can be explained by projecting them onto admissible actions in the control basis. The human collaborator can be informed by predictions about future states that result from autonomous behavior. Adaptive interfaces, such as these, allow collaborators to communicate regarding future intentions.
Copyright Laboratory for Perceptual Robotics.